KarpathyのLLM Wiki完全解説:RAGを超える知識コンパイル設計とは

くろこちゃん

- LLM Wikiとは何か:定義と背景
- 3層アーキテクチャ:構造の全体像
- Layer 1(raw/):不変の原始データ保管庫
- Layer 2(Wiki/):LLMが生成・保守するMarkdown集
- Layer 3(Schema):運用ガイドライン
- 3つの運用サイクルと発展パス:LLM Wikiが「育つ」仕組み
- Ingest(取り込み)
- Query(照会・拡張)
- Lint(保守・整合性チェック)
- 将来展望:知識蒸留パス
- RAGとLLM Wiki:根本的な違い
- 技術スタック:何を使って実装するか
- デメリットと限界:過信しないために知っておくこと
- LLM Wikiが適している用途
- FAQ
- まとめ:今すぐ試せる次のアクション
- お気軽にご相談ください
- 参考情報
LLMを「クエリに答えるツール」として使うのをやめ、「知識を継続的に書き込む司書」として機能させる。これが、Andrej Karpathyが2026年4月3〜4日にGitHub Gistで公開した「LLM Knowledge Bases(LLM Wiki)」の核心だ。
Karpathy自身はこのアーキテクチャを使い、直近の研究トピックに関するWikiをすでに約100記事・約40万語まで育てている。RAGが「倉庫から検索する」構造であるのに対し、LLM Wikiは「知識を編集済み百科事典としてコンパイルし続ける」構造だ。この違いは思ったよりずっと深い。
LLM Wikiとは何か:定義と背景
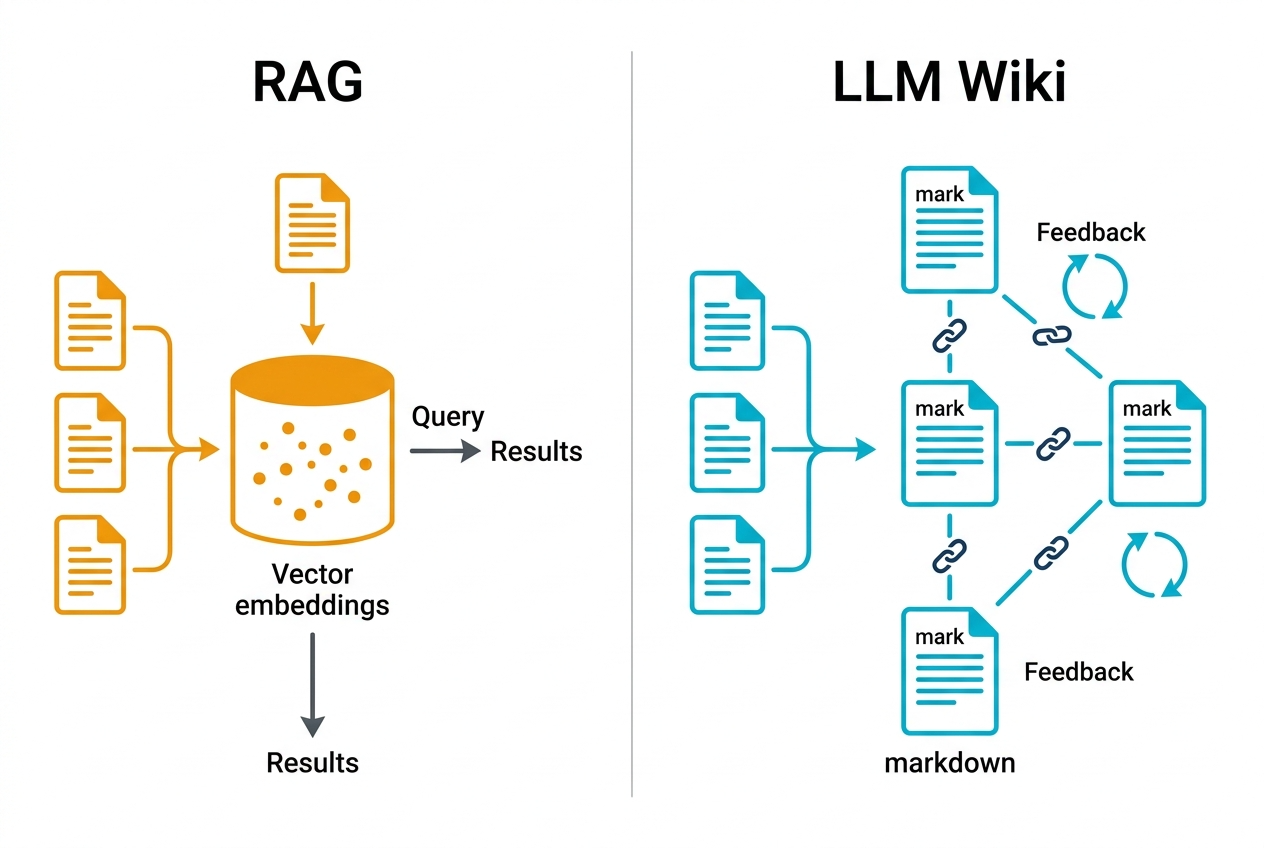
LLM Knowledge Bases(LLM Wiki)とは、LLMエージェントがMarkdown形式のWikiを自律的に構築・保守・更新するナレッジ管理アーキテクチャである。RAGの代替として設計されたこのアプローチは、知識を「検索して参照する」のではなく「コンパイルして蓄積する」点で根本的に異なる。
開発者・研究者がドキュメントや論文を読むとき、その内容を「読む」のは難しくない。難しいのはブックキーピング(記録・整理)だ。読んだ内容をどこかに書き留め、関連する過去の情報と紐付け、時間が経って情報が古くなれば更新する。この「面倒な部分」をLLMに委譲するというのがKarpathyのアイデアである。
従来のRAGアーキテクチャでは、ドキュメントをベクトル化して埋め込み、クエリのたびに類似検索して文脈を取得する。これは「その場限りのステートレスな参照」だ。LLM Wikiは対照的に、参照のたびに知識をWikiに書き戻す。知識は蓄積し、次のクエリはより豊かな文脈から回答が生成される。Karpathyはこれを「複利効果(compound interest)」と表現している(出典:GitHub Gist)。
3層アーキテクチャ:構造の全体像
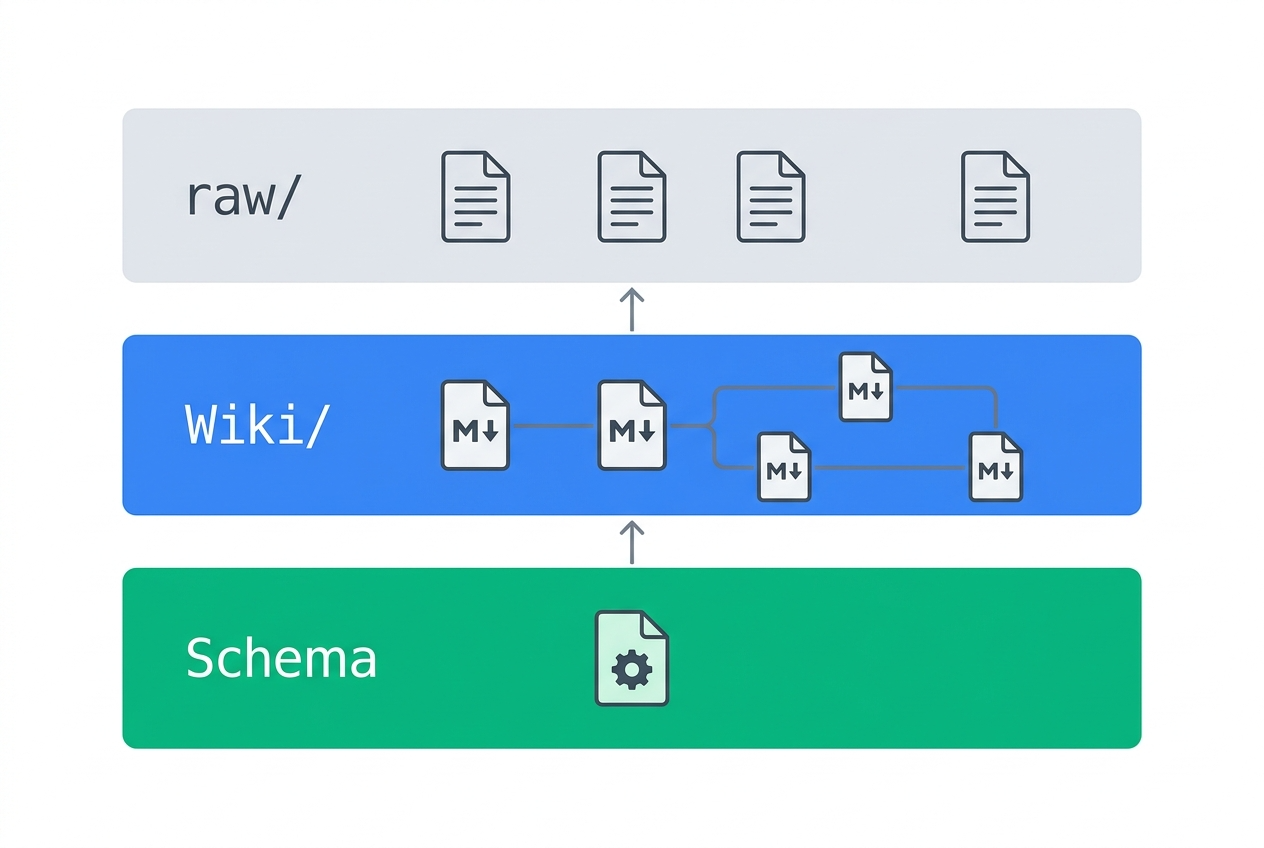
LLM Wikiは3つの層から構成される。
Layer 1(raw/):不変の原始データ保管庫
論文・GitHubリポジトリ・記事などをMarkdown形式で格納する層。ここへの書き込みは人間またはIngestion処理のみが行い、LLMによる変更は加えない。元データの汚染を防ぐ設計だ。ObsidianのWeb Clipperを使えば、ブラウザから直接Markdownに変換して取り込める。
Layer 2(Wiki/):LLMが生成・保守するMarkdown集
LLMが書き込む層。概念記事・百科事典スタイルのエントリ・バックリンクで構成される。ここが本アーキテクチャの中心だ。ファイルはすべて人間が読めるMarkdownであり、Gitでバージョン管理する。ベクトルDBは使わない。
Layer 3(Schema):運用ガイドライン
CLAUDE.mdまたはAGENTS.mdとして記述された構造定義と作業フローのドキュメント。「どのエージェントが何をする権限を持つか」「Wikiにどんなフォーマットでエントリをつくるか」を規定する。エージェントの行動憲法にあたる。
3つの運用サイクルと発展パス:LLM Wikiが「育つ」仕組み
Ingest(取り込み)
新しいソース1件をraw/に追加したとき、LLMが関連する10〜15のWikiページを同時更新する。「読んで終わり」ではなく、読んだ内容が即座にWikiに反映される。
Query(照会・拡張)
質問に回答した際、その回答・知見をWiki内の新しいページとして書き戻す。回答そのものがWikiを成長させる。「使うほど賢くなる」仕組みが運用の中心にある。
Lint(保守・整合性チェック)
定期的にLLMがWiki全体をスキャンし、矛盾・古くなった記述・重複エントリを検出して修正する。知識ベースの品質が自律的に維持される。
将来展望:知識蒸留パス
Karpathyは設計の将来パスとして、LLM Wikiが合成Q&Aデータの生成源となり、ドメイン特化モデルのファインチューニングデータとして活用できる段階を想定している。Wiki → 合成Q&A → ファインチューニングという知識蒸留の流れは、Gistに明示的に記述されている(出典:GitHub Gist)。
RAGとLLM Wiki:根本的な違い
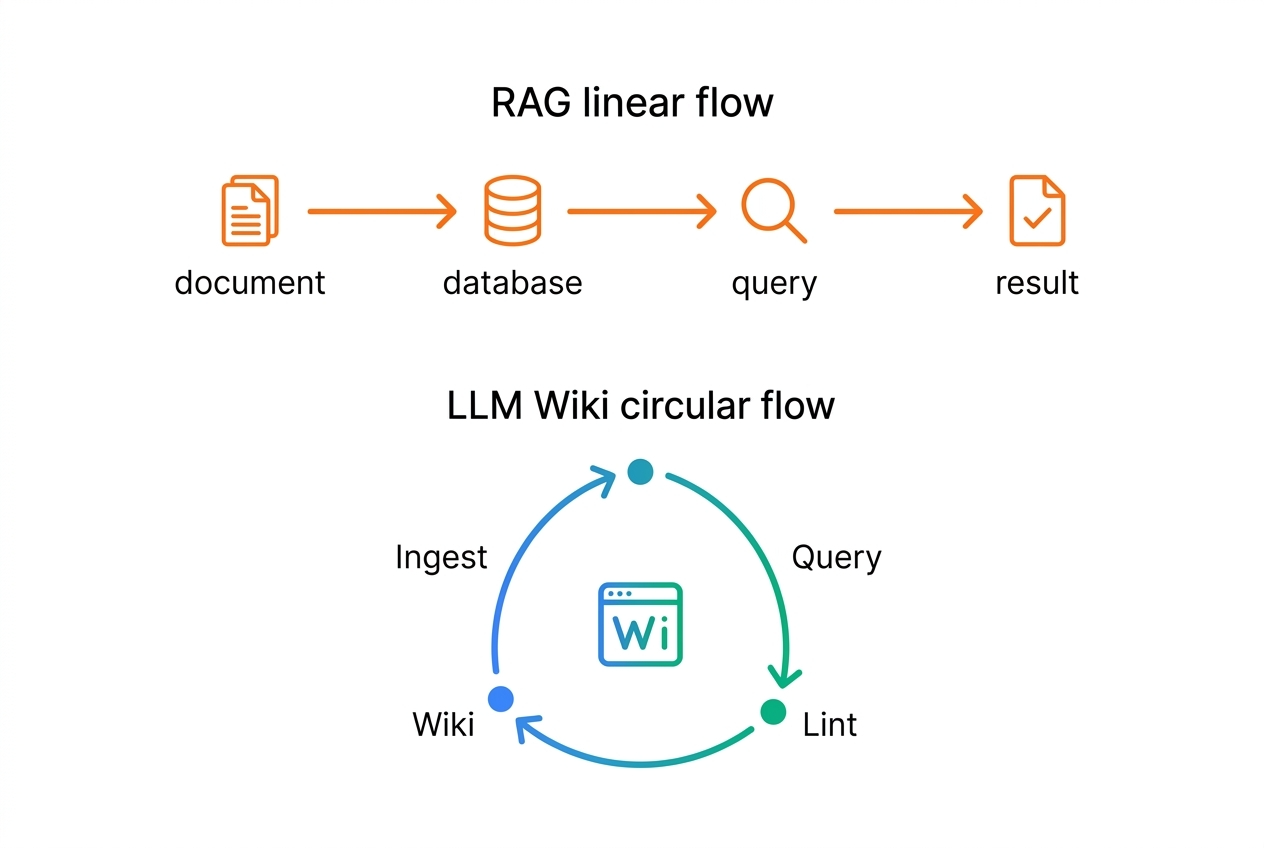
「RAGの改良版」として捉えるのは正確ではない。両者はドキュメントへの向き合い方が根本から異なる。
| 観点 | 従来のRAG | LLM Wiki |
|---|---|---|
| データ形式 | 不透明な埋め込み(ベクトル) | 人間が読めるMarkdown |
| 論理の表現 | ベクトル空間で近似的に創発 | 明示的なインデックスとバックリンク |
| 監査性 | 限定的 | 完全(ファイルレベルで透明) |
| 知識の更新 | 静的・定期再インデックスが必要 | Lintにより継続的に精緻化 |
| 適正スケール | 数百万件の異種大量ドキュメント | 数百〜数万件の高品質ドキュメント |
техbuddies.ioが「倉庫(RAG)vs 図書館(LLM Wiki)」と表現したのは的確だ。倉庫には大量のモノを詰め込める。しかし図書館は、本の位置を知っていて、読んでいて、書き直しながら体系を維持する司書がいる。
RAGは「検索して参照する」システムだ。LLM Wikiは「読んで書き込み、体系を育てる」システムだ。クエリのたびに知識が積み上がり、次のクエリがより豊かになる。この「知識のコンパイル」という概念こそが、LLM Wikiを単なる検索最適化と分かつ核心だ。
技術スタック:何を使って実装するか
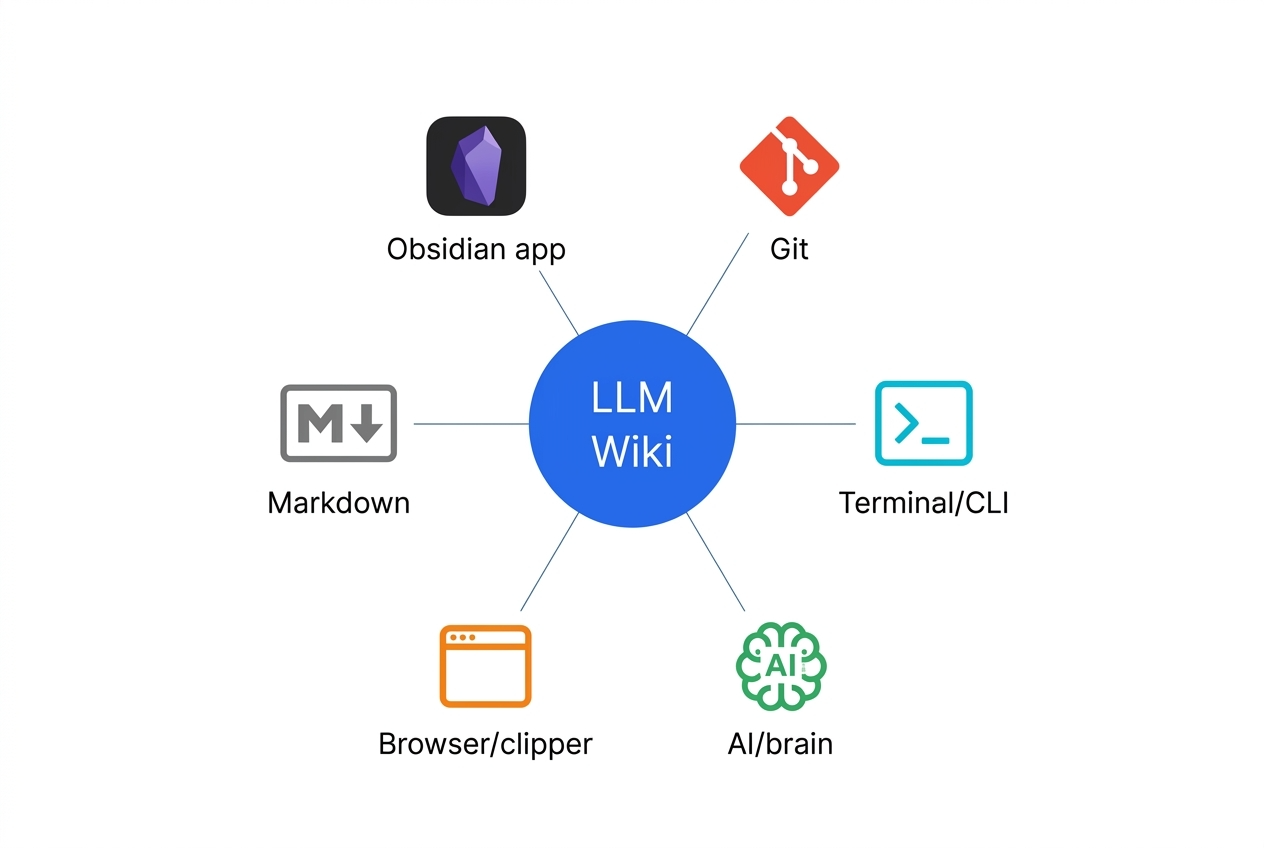
LLM Wikiを実装するために必要なツールは以下の通りだ。特別な商用サービスへの依存はなく、ローカル完結できる。
- Obsidian:WikiのMarkdownファイルを閲覧・管理するビューア。グラフビューでバックリンクを可視化できる。
- Obsidian Web Clipper:ブラウザからWebページをMarkdownに変換してraw/へ取り込む。
- Git:Wikiのバージョン管理。変更履歴を完全に保持する。
- qmd CLI:BM25 + ベクトル検索 + LLM再ランキングを組み合わせたハイブリッド検索。WikiをクエリするCLIツール。
- LLMエージェント:Claude Code、OpenAI Codexなど。WikiのIngest・Lint処理を担う。
ファイル形式は純粋なMarkdownのみ。ベクトルDBは不要だ。これは監査性と移植性の面で大きなアドバンテージになる。
デメリットと限界:過信しないために知っておくこと
LLM Wikiには明確な限界がある。導入前に理解しておくべき3点を挙げる。
スケール限界:適正規模は数百〜数万件の高品質ドキュメントだ。LLMがWiki全体を参照して整合性を保つ設計上、ドキュメント数が増えるほどコンテキスト管理のコストが上昇する。数百万件の異種ドキュメントを網羅的に扱うエンタープライズ知識管理には、RAGのほうが適している。
幻覚汚染リスク:LLMが誤った接続や不正確な情報をWikiに書き込んだ場合、それ以降のすべてのクエリがその誤情報を参照しうる。定期的なLintだけでは検出しきれないケースもある。Wikiに人間がレビューできる体制を組み込むことが現実的な対策になる。
技術障壁:スクリプト構成が複雑であり、エンジニア以外がセットアップするのは容易ではない。現時点では開発者・研究者向けのツールだ。
データ品質依存:raw/への入力品質がパイプライン全体の上限を決定する。低品質なドキュメントを大量に投入しても、Wikiの質は上がらない。
LLM Wikiが適している用途
このアーキテクチャの適正ユースケースはかなり明確だ。
- 個人の研究・学習:論文・技術情報の長期蓄積と体系化。Karpathy自身のユースケースがこれだ。
- 特定ドメインの専門知識体系構築:医療・法律・特定技術分野など、深い専門知識を継続的に整理したい場合。
- 人間が監査・編集できる形で知識を維持したい場合:ベクトルDBの「ブラックボックス」に不安を感じる組織に向いている。
- 将来的にファインチューニングデータ源として使いたい場合:Karpathyが設計に組み込んだ知識蒸留パスを活用したいケース。
FAQ
Q1. LLM Wikiを試すために必要な最低限のセットアップは?
Obsidian(無料)、Git、任意のLLMエージェント(Claude CodeやOpenAI Codexの無料枠でも動作可能)の3点で始められる。Obsidian Web ClipperはChrome/Firefox拡張として無料で入手できる。qmd CLIはオプションだが、検索品質を上げたい場合には導入を推奨する。一次ソースのGitHub Gistにフォルダ構成とCLAUDE.mdの書き方のサンプルが含まれている。
Q2. RAGを既に使っている場合、LLM Wikiに移行すべきか?
用途による。数百万件の多様なドキュメントを検索する用途(社内ドキュメント全般の検索など)にはRAGのほうが適している。個人の研究ノートや特定ドメインの深い専門知識管理であれば、LLM Wikiのほうが知識の蓄積と監査性の面で優れる。二者択一ではなく、用途に応じて使い分ける選択肢もある。
Q3. LLMが誤情報をWikiに書き込んだ場合、どう対処するか?
Gitでバージョン管理しているため、誤情報を含むコミットはロールバックできる。また、Lintサイクルで矛盾検出を定期実行することが推奨されている。ただし、LLMが一貫して誤った前提を持っている場合はLintで検出しにくい。重要なドメインでは人間のレビューサイクルを組み込むことが現実的な対策だ。
Q4. Karpathyの40万語のWikiはどのくらいの期間で構築されたか?
GitHub Gistで明示的な期間は示されていないが、「直近の研究トピック」における蓄積として紹介されている。1日あたりの論文・記事のIngestionペースと関連するWikiページ数(1ソースあたり10〜15ページ)から逆算すると、数ヶ月規模での構築が現実的な水準と推定される。
Q5. LLMのコンテキストウィンドウを超えるWikiサイズになったらどうなるか?
qmd CLIが提供するBM25 + ベクトル + LLM再ランキングのハイブリッド検索で、クエリに関連するWikiエントリだけを絞り込んでコンテキストに渡す設計になっている。Wiki全体をコンテキストに収める必要はない。Karpathyの約40万語のWikiも、このアーキテクチャで運用されている。
Q6. 企業での導入を検討する場合の注意点は?
現時点では技術障壁が高く、エンジニアが複数いるチームでの試験的導入から始めるのが現実的だ。幻覚汚染リスクへの対策として、Wikiへの書き込みに人間のレビューゲートを設けることを推奨する。また、raw/には機密情報の取り扱いに注意が必要だ。LLMエージェントが参照するドキュメントにどんな情報が含まれるかは、セキュリティポリシーと照らし合わせて判断する。
まとめ:今すぐ試せる次のアクション
LLM Wikiは「RAGの代替」ではなく、知識管理の設計思想そのものを変える提案だ。ステートレスな検索から、コンパイルされ続ける知識体系へ。Karpathyが40万語のWikiを実証として示したことで、このアーキテクチャは「面白い概念」から「再現可能な実践」に変わった。
試したい場合の具体的な手順は以下の通りだ。
- GitHub Gistを読み、フォルダ構成(raw/ / Wiki/ / Schema/)を手元に再現する
- Obsidianで
Wiki/フォルダを開き、グラフビューでバックリンク管理を確認する - Obsidian Web Clipperで気になる記事や論文を1本raw/に取り込む
- Claude Codeや任意のLLMエージェントに
CLAUDE.mdを読ませ、Ingestを実行させる - 1週間後、Wikiがどう育っているかを確認する
知識は読むだけでは蓄積しない。書き直され、整理され、バックリンクで結ばれてはじめて「使える資産」になる。そのブックキーピングをLLMに任せる時代が、静かに始まっている。
お気軽にご相談ください
AIを使った業務効率化、社内ツール開発、既存プロダクトへのAI機能追加、受託開発全般——上流の企画段階から実装・運用まで、まとめてご相談いただけます。
「これってAIで解決できるの?」「どこから手をつければいい?」という入口のご相談大歓迎です。
具体的な仕様が固まる前の壁打ちフェーズからぜひお気軽にご相談ください。
参考情報
- Andrej Karpathy「LLM Knowledge Bases」GitHub Gist(https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f)